آزمایش رابط های مغز و کامپیوتر در جاوا اسکریپت.
آزمایش رابط های مغز و کامپیوتر در جاوا اسکریپت.
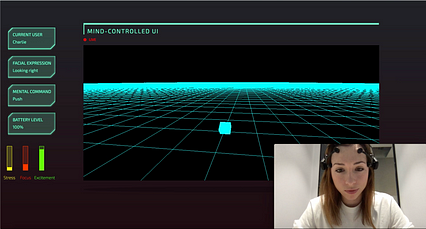 مغز- رابط رایانه ای با یک Emotiv Epoc
مغز- رابط رایانه ای با یک Emotiv Epoc طی دو سال گذشته ، من علاقه فزاینده ای به فناوری عصبی داشتم. این پست وبلاگ درباره به اشتراک گذاشتن چیزهایی است که در طول راه آموخته ام و امیدوارم به افرادی که می خواهند شروع کنند کمک کند!
قبل از ورود به این موضوع ، فکر کردم به طور مختصر در مورد نحوه ورود به آن صحبت کنم. در وهله اول. با انجام یک bootcamp برنامه نویسی همه جانبه در مجمع عمومی ، کد نویسی را یاد گرفتم.
در حالی که به دنبال اولین کارم بودم ، با جاوا اسکریپت و سخت افزار شروع به کار کردم و اولین پروژه ای که من روی آن کار کردم کنترل رباتیک Sphero بود. توپ با استفاده از حرکات دست من روی یک حرکت جهشی.
 حرکت- Sphero کنترل شده با حرکت جهشی
حرکت- Sphero کنترل شده با حرکت جهشی اولین باری بود که از JavaScript برای کنترل چیزهای خارج از مرورگر استفاده می کردم و فوراً گیر می کردم!
از آن زمان ، من هزینه های زیادی را صرف کرده ام از زمان شخصی من نمونه سازی پروژه های تعاملی و هر بار ، من tr y تا کمی بیشتر خودم را به چالش بکشم تا چیز جدیدی یاد بگیرم.
پس از آزمایش چند دستگاه مختلف ، به دنبال چالش بعدی خود بودم و این زمانی بود که با اولین سنسور مغزی خود ، یعنی Neurosky ، برخورد کردم.
اولین آزمایشات با یک سنسور مغزی
- -
هنگامی که به آزمایش با سنسورهای مغزی علاقه مند شدم ، تصمیم گرفتم با خرید یک Neurosky شروع کنم زیرا بسیار ارزان تر از سایر گزینه ها بود.
 حسگر مغز عصبی
حسگر مغز عصبی من واقعاً نمی دانستم آیا مهارت برنامه ریزی هر چیزی برای آن را دارم (تازه بوتکامپ برنامه نویسی خود را تمام کرده بودم) ، بنابراین نمی خواستم پول زیادی هدر دهم. خوشبختانه ، قبلاً یک چارچوب جاوا اسکریپت برای Neurosky ساخته شده بود ، بنابراین من می توانم به راحتی شروع کنم. من روی سطح تمرکز خود برای کنترل یک هواپیمای بدون سرنشین Sphero و Parrot AR کار کردم.
به سرعت متوجه شدم که این سنسور مغزی فوق العاده دقیق نیست. این دستگاه فقط 3 سنسور دارد ، بنابراین سطح "توجه" و "میانجیگری" خود را به شما می دهد ، اما به روشی کاملاً نامنظم. آنها همچنین به شما امکان دسترسی به داده های خام حاصل از هر سنسور را می دهند ، بنابراین می توانید چیزهایی مانند تجسم کننده بسازید ، اما 3 سنسور واقعاً برای نتیجه گیری در مورد آنچه در مغز شما اتفاق می افتد کافی نیست.
هنگامی که در حال تحقیق در مورد دیگر حسگرهای مغزی بودم ، با Emotiv Epoc برخورد کردم. به نظر می رسید که ویژگی های بیشتری دارد ، بنابراین تصمیم گرفتم آن را بخرم تا بتوانم با BCI ها آزمایش کنم.
قبل از توضیح نحوه عملکرد این هدست ، اجازه دهید به طور مختصر در مورد مغز صحبت کنیم.
چگونه آیا مغز کار می کند
- -
من قطعاً متخصص علوم اعصاب نیستم بنابراین توضیحات من ناقص خواهد بود اما اگر می خواهید چند نکته اساسی وجود دارد که باید بدانید برای درک بهتر حسگرهای مغزی و فناوری عصبی.
مغز از میلیاردها و میلیاردها نورون ساخته شده است. این نورون ها سلول های تخصصی هستند که اطلاعات را پردازش می کنند و به جای اینکه به طور تصادفی پخش شوند ،ما می دانیم که مغز در قسمتهای مختلف مسئول عملکردهای مختلف فیزیولوژیکی سازماندهی شده است.
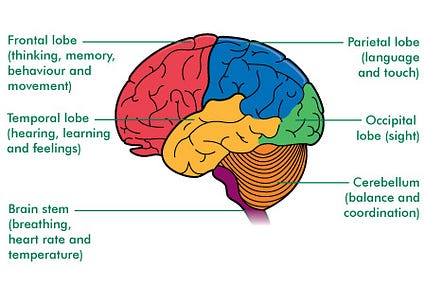 قسمتهای مختلف مغز (منبع: macmillan.org.uk)
قسمتهای مختلف مغز (منبع: macmillan.org.uk) برای مثال ، بیایید: حرکت کنیم.
در مغز ، قسمتهایی که مسئول حرکت و هماهنگی هستند عبارتند از: قشر حرکتی اولیه (در لوب پیشانی) و مخچه. هنگام هماهنگی حرکات ، نورون های این قسمت ها فعال می شوند و آکسون های خود را به نخاع می فرستند. آنها سپس نورونهای حرکتی را فعال می کنند که عضلات را فعال کرده و منجر به حرکت می شوند.
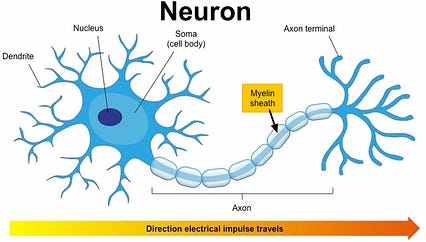 آناتومی neuron
آناتومی neuron همانطور که قبلاً گفتم ، این توضیح بسیار ساده است ، اما مهمترین چیز این است که این سیگنالهای الکتریکی شلیک شده را می توان در واقع توسط دستگاه EEG (الکتروانسفالوگرافی) در سطح پوست سر پیگیری کرد.
از سایر سیستم ها می توان برای ردیابی فعالیت مغز استفاده کرد ، اما معمولاً بسیار تهاجمی ، گران قیمت هستند و نیاز به جراحی دارند. به عنوان مثال ، شما همچنین ECog (الکتروکورتیکوگرافی) دارید که در آن ایمپلنت ها داخل جمجمه قرار می گیرند.
امیدوارم این امر منطقی باشد و اکنون می توانیم مدتی را در مورد نحوه ردیابی این سیگنال های الکتریکی Emotiv Epoc صرف کنیم.
حسگر مغز چگونه کار می کند
- -
Emotiv دارای 3 دستگاه مختلف است:
Epoc دارای 14 سنسور (که به آن کانال ها نیز گفته می شود) در اطراف سر قرار گرفته است.
10/20 سیستم بین المللی EEG (در سمت چپ پایین) ، به عنوان مرجعی برای توصیف و اعمال مکان الکترودهای پوست سر استفاده می شود. این بر اساس رابطه بین محل الکترود و ناحیه زیرین مغز است. به این ترتیب ، استاندارد خاصی را در دستگاه ها و آزمایش های علمی امکان پذیر می کند.
در رنگ های سبز و نارنجی ، می توانید ببینید کدام حسگرها در Epoc (در سمت راست) استفاده می شوند.
 10/20 سیستم بین المللی EEG در مقابل Emotiv Epoc
10/20 سیستم بین المللی EEG در مقابل Emotiv Epoc همانطور که می بینید ، حتی اگر 14 کانال ممکن است زیاد به نظر برسند ، در واقع بسیار کمتر از میزان سنسورهای یک دستگاه پزشکی است ، با این حال ، به نظر می رسد که آنها به خوبی در اطراف سر توزیع شده اند.
میزان نمونه گیری Epoc از 2048 نمونه داخلی با 128 SPS یا 256 SPS نمونه گیری می شود و پاسخ فرکانسی بین 0.16 تا 43 هرتز است.
این بدان معناست که 2048 نمونه در ثانیه از سیگنال پیوسته گرفته می شود که در آن فرکانس پاسخ متفاوت است. از 0.16Hz تا 43Hz.
اگر به انواع مختلف امواج مغزی نگاه کنیم ، می بینیم که آنها بین 0.5Hz تا 100Hz کار می کنند.
 Ty pes امواج مغزی
Ty pes امواج مغزی چرا این مهم است؟ از آنجا که بسته به نوع برنامه ای که می خواهیم با دستگاه خود بسازیم ، ممکن است بخواهیم فقط بر روی امواج خاصی تمرکز کنیم که روی فرکانس های خاصی کار می کنند. به عنوان مثال ، اگر می خواهیم یک برنامه مدیتیشن بسازیم ، ممکن است بخواهیم فقط روی امواج تتا تمرکز کنیم که بین 4 تا 8 هرتز کار می کنند.
اکنون که می دانیم دستگاه چگونه کار می کند ، بیایید در مورد کارکرد آن صحبت کنیم. به شما این امکان را می دهد که ردیابی کنید. سنسور در عوض ، آنها به شما دسترسی می یابند: > حالات صورت (پلک زدن ، چشمک زدن به چپ و راست ،غافلگیری ، اخم ، لبخند ، فشار دادن ، خندیدن ، پوزخند زدن)
فقط دستورات ذهنی به آموزش هر کاربر نیاز دارد. برای آموزش این "افکار" ، باید نرم افزار آنها را بارگیری کنید.
پس از آموزش ، یک فایل به صورت محلی یا در ابر ذخیره می شود.
در صورت تمایل برای نوشتن برنامه خود ، می توانید از API Cortex ، SDK انجمن آنها استفاده کنید (پس از v3.5 حفظ آن را متوقف کردند) یا اگر می خواهید از JavaScript استفاده کنید ، می توانید از چارچوبی که من روی آن کار کرده ام ، epoc.js.
Epoc.js
- -
Epoc.js چارچوبی برای تعامل با Emotiv Epoc و Insight در جاوا اسکریپت است. به شما امکان می دهد به همان ویژگی های ذکر شده در بالا (داده های شتاب سنج/ژیروسکوپ ، معیارهای عملکرد ، حالات چهره و دستورات ذهنی) دسترسی داشته باشید و همچنین به شما امکان می دهد با شبیه ساز تعامل داشته باشید.
شما فقط به چند خط نیاز دارید کد برای شروع:
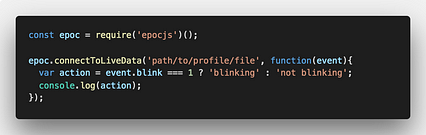 نمونه کد
نمونه کد در نمونه کد بالا ، ما با نیاز و نمونه سازی ماژول گره شروع می کنیم. سپس متد را connectToLiveData می نامیم و آن را به فایل کاربری که پس از آموزش ذخیره می شود ارسال می کنیم. ما با یک شیء حاوی ویژگی های مختلفی که می توانیم آنها را دنبال کنیم ، تماس تلفنی دریافت می کنیم. به عنوان مثال ، اگر می خواهیم کاربر چشمک بزند یا نه ، از event.blink استفاده می کنیم.
هر ویژگی اگر فعال نشود یا 0 باشد در صورت فعال شدن برمی گردد. < /p>
لیست کامل خواص موجود را می توانید در README مخزن پیدا کنید.
در پس زمینه ، این چارچوب با استفاده از Emotiv C ++ SDK ، Node.js و 3 ماژول گره ساخته شده است. : Node-gyp ، Bindings و Nan.
این روش قدیمی ایجاد یک node-addon است ، بنابراین اگر علاقمند به کسب اطلاعات بیشتر در مورد آن هستید ، توصیه می کنم به N-API مراجعه کنید.
بنابراین ، اکنون که در مورد ویژگی های مختلف و نحوه شروع کار صحبت کردیم ، در اینجا چند نمونه اولیه وجود دارد که من تا به حال ساخته ام.
نمونه های اولیه
- -
1. صفحه کلید مغز
 نمایشی برای نوشتن با استفاده از حرکات چشم
نمایشی برای نوشتن با استفاده از حرکات چشم اولین نسخه ی نمایشی که من با Emotiv Epoc ساخته بودم یک صفحه کلید مغز بود. هدف این بود که ببینم آیا می توانم یک رابط سریع بسازم تا مردم بتوانند با استفاده از حالات چهره با یکدیگر ارتباط برقرار کنند.
با استفاده از حرکات چشم ، نگاه به راست یا چپ ، حرف راست/چپ برجسته می شود و چشمک زدن ، نامه را انتخاب می کند. و آن را در قسمت ورودی نمایش می دهد.
این یک نمونه اولیه بسیار ساده است اما کار می کند !!
2. WebVR
نمونه دوم من شامل دستورات ذهنی است. می خواستم ببینم آیا فقط با استفاده از افکار می توانم در یک فضای سه بعدی حرکت کنم.
 مغز -رابط وب رایانه
مغز -رابط وب رایانه در این نمونه اولیه ، من از Three.js برای ایجاد صحنه اصلی سه بعدی ، epoc.js برای ردیابی دستورات ذهنی و سوکت های وب برای ارسال آنها از سرور به قسمت جلو استفاده کردم.
3. IoT
سومین نمونه اولیه من در مورد کنترل سخت افزار در جاوا اسکریپت است. این چیزی است که من چند سال با آن سر و کار داشتم ، بنابراین من مشتاق بودم که یک پروژه سریع برای کنترل یک پهپاد کوچک طوطی با استفاده از افکار بسازم!

همه این نمونه های اولیه بسیار کوچک هستند. هدف اصلی تأیید برخی ایده ها و آشنایی با امکانات و محدودیت های چنین فناوری بودبیایید با صحبت در مورد محدودیت ها شروع کنیم. p>
آموزش
این واقعیت که هر کاربر مجبور است جلسات آموزشی را برای ثبت امواج مغزی و تطبیق آنها با دستورات خاص بگذراند ، انتظار می رود اما برای اکثر افراد مانعی برای فرزندخواندگی است. مگر اینکه یک برنامه نیاز واقعی را برطرف کند و دقت دستگاه واقعاً خوب باشد ، نمی توانم تصور کنم که مردم برای آموزش سنسور مغز وقت صرف کنند.
تاخیر
هنگام ساخت نمونه اولیه من با استفاده از دستورات ذهنی ، متوجه شدم که بین شروع به فکر کردن در مورد یک فکر خاص و لحظه ای که می توانم بازخورد برنامه خود را ببینم ، کمی تأخیر وجود دارد.
فرض می کنم این به این دلیل است که از الگوریتم یادگیری ماشین استفاده می شود در پس زمینه داده ها را در زمان واقعی از دستگاه دریافت می کند و قبل از اینکه بتوانید افکار فعلی را بر اساس افکار قبلی آموزش دهید طبقه بندی کنید تا مدت زمان مشخصی به نمونه نیاز دارد.
این امر بر نوع برنامه شما تأثیر می گذارد می تواند با سنسور ساخته شود به عنوان مثال ، ساختن یک برنامه مدیتیشن خوب است زیرا تأخیر تأثیر مهمی بر تجربه کاربر نخواهد داشت ، اما اگر می خواهید یک ویلچر با کنترل فکر بسازید ، می توانید تصور کنید که چگونه تأخیر می تواند تأثیر بسیار مهمی داشته باشد. < /p>
دستگاه های EEG تهاجمی در مقابل غیر تهاجمی
بسیار عالی هستند زیرا نیازی به جراحی ندارید. فقط هدست را بگذارید ، مقداری ژل به سنسورها اضافه کنید و آماده حرکت هستید! با این حال ، عدم تهاجم بودن این بدان معناست که سنسورها باید سیگنال های الکتریکی را از طریق جمجمه ردیابی کنند ، که باعث می شود این روش کارایی کمتری داشته باشد.
وضوح زمانی واقعاً خوب است زیرا میزان نمونه گیری بسیار سریع است وضوح فضایی عالی نیست دستگاه های EEG فقط می توانند فعالیت مغز را در سطح پوست سر ردیابی کنند ، بنابراین فعالیت هایی که کمی در عمق مغز اتفاق می افتند قابل پیگیری نیست.
پذیرش اجتماعی
استفاده از سنسور مغزی پر زرق و برق ترین چیز تا زمانی که دستگاه ها ظاهر خود را داشته باشند ، فکر نمی کنم که توسط مصرف کنندگان پذیرفته شوند. با پیشرفت فناوری ، ممکن است بتوانیم دستگاه هایی بسازیم که در لوازم جانبی مانند کلاه پنهان شوند ، اما هنوز مشکل دیگری وجود دارد ، حسگرهای مغزی پس از چند دقیقه ناراحت می شوند.
به عنوان دستگاه EEG غیر تهاجمی ، سنسورها باید کمی فشار روی پوست سر وارد کنند تا سیگنال های الکتریکی را بهتر ردیابی کنند. همانطور که می توانید تصور کنید ، این فشار جزئی در ابتدا خوب است ، اما به تدریج با گذشت زمان ناراحت کننده می شود. علاوه بر این ، اگر دستگاهی نیاز به ژلی دارد که روی همه سنسورها اعمال می شود ، این مانع دیگری برای استفاده افراد از آن است.
حتی اگر وضعیت فعلی سنسورهای EEG آنها را در دسترس یا جذاب برای اکثر افراد قرار ندهد ، در آنجا وجود دارد. هنوز برخی از امکانات جالب برای آینده هستند. ما می توانیم چند برنامه مختلف را در نظر بگیریم.
دسترس پذیری
من دوست دارم حسگرهای مغزی به افراد دارای نوعی معلولیت کمک کنند که زندگی بهتری داشته باشند ومستقل تر باشید.
این چیزی بود که من هنگام ساخت اولین نمونه اولیه صفحه کلید مغز در ذهن داشتم. من می دانم که نمونه اولیه به پایان نرسیده است ، اما من واقعاً علاقه داشتم ببینم آیا یک دستگاه مصرف کننده عمومی می تواند به مردم کمک کند. همه به سیستم های پیچیده پزشکی دسترسی ندارند و من واقعاً هیجان زده بودم که دیدم دستگاه در دسترس تری که می توانید بصورت آنلاین خریداری کنید واقعاً می تواند کمک کننده باشد!
ذهن آگاهی
برنامه ای که در حال حاضر تمرکز برخی از حسگرهای مغزی (به عنوان مثال ، Muse) تمرکز حواس است.
مدیتیشن می تواند مشکل باشد. سخت است بدانید که آیا این کار را به درستی انجام می دهید یا خیر. حسگرهای مغزی می توانند به مردم کمک کنند تا بازخورد مستقیم خود را در مورد نحوه عملکرد خود داشته باشند یا حتی راهنمایی در مورد نحوه بهبود در طول زمان داشته باشند.
پیشگیری
اگر از حسگرهای مغزی به اندازه ما استفاده شود از تلفن های خود استفاده کنیم ، احتمالاً می توانیم برنامه هایی بسازیم که بتوانند در مواقعی که برخی عملکردهای فیزیولوژیکی آنطور که باید کار نمی کنند ، ردیابی کنند. برای مثال ، اگر بتوانیم الگوریتم های تشخیص را برای جلوگیری از سکته مغزی ، حملات اضطرابی یا حملات صرع بر اساس فعالیت مغزی بسازیم ، بسیار عالی خواهد بود. مدیتیشن ، آنها همچنین می توانند زمان هایی از روز را که بیشترین تمرکز را در آنها دارید ، پیگیری کنند. اگر ما مرتباً از سنسور استفاده می کردیم ، در نهایت می توانست به ما بگوید که چه زمانی باید کارهای خاصی را انجام دهیم. حتی می توانید تصور کنید که برنامه شما بر این اساس تنظیم می شود تا مطمئن شوید روزهای شما پربارتر است.
هنر
من تقاطع تکنولوژی و هنر را به عنوان راهی برای کشف چیزها دوست دارم. مجبور به انجام کار نباشید من واقعاً فکر می کنم که ساختن چیزهای خلاقانه با سنسورهای مغزی نباید دست کم گرفته شود زیرا به ما امکان می دهد قبل از استفاده از یک برنامه کاربردی مفیدتر ، امکانات و محدودیت های مختلف فناوری را کشف کنیم.
ترکیب با سایر حسگرها
من اخیراً به این موضوع فکر کردم که سنسورهای مغزی نباید به طور مستقل درمان شوند. مغز جهان را فقط از طریق سایر قسمتهای بدن درک می کند ، بدون چشم نمی بیند ، بدون گوش نمی شنود و غیره ... بنابراین اگر می خواهیم امواج مغزی را معنا کنیم ، احتمالاً باید سایر عملکردهای بیولوژیکی را نیز دنبال کنیم. .
مسأله اصلی در این مورد این است که ما به تنظیماتی می رسیم که به این شکل هستند:
 شناختی
شناختی و ما می توانیم مطمئن باشیم هیچ کس به طور روزانه از آن استفاده نمی کند ...
بعدی
- -
چند هفته پیش ، یک سنسور مغزی جدید ، OpenBCI خریدم. گام بعدی من این است که با داده های خام و یادگیری ماشین کار کنم ، بنابراین فکر کردم این دستگاه برای آن کاملاً مناسب است زیرا کاملاً منبع باز است.
من فقط وقت داشتم آن را راه اندازی کنم ، بنابراین من هرگز " هنوز چیزی با آن ساخته نشده است ، اما در اینجا پیش نمایش کوچکی از ظاهر دستگاه و رابط کاربری است.
 OpenBCI
OpenBCI فعلا همین!
متوجه شدم که این یک پست طولانی است بنابراین اگر همه چیز را خوانده اید ، بسیار متشکرم!
در حال یادگیری هستم ، بنابراین اگر نظری ، بازخورد دارید یا می خواهید منابع را به اشتراک بگذارید ، خیالتان راحت باشد!
منابع
- -
در اینجا یک چند پیونداگر می خواهید برخی از ابزارها را امتحان کنید یا بیشتر بیاموزید!
چارچوب
Epoc.js - چارچوب جاوا اسکریپت برای تعامل با Emotiv Epoc.
بیت مغز - A مکانیسم املایی آنلاین P300 برای هدست Emotiv.
Wits - کتابخانه ای Node.js که با هدست Emotiv EPOC EEG ذهن شما را می خواند.
مانیتور مغزی - یک برنامه پایانی نوشته شده در Node.js برای نظارت بر سیگنال های مغزی در زمان واقعی.
Ganglion BLE-سرویس گیرنده بلوتوث وب برای رابط مغز و کامپیوتر Ganglion توسط OpenBCI. جاوا اسکریپت.
پیوندهای مفید
NeurotechX
رابط مغز و کامپیوتر (کتاب)
اصول علوم عصبی (کتاب)
مقدمه ای از Techy برای علوم اعصاب - Uri Shaked
تشخیص وضعیت فعالیت مغز با استفاده از رابط کامپیوتر مغز - ویاچسلاو نستروف
افراد
الکس کاستیلو
Andrew Jay Keller
Conor Russomano
Uri Shaked
Nataliya Kosmyna
- -
چرا مدل پوست تیره کامپیوتری بهتر از واقعی
 من جعلی هستم
من جعلی هستم چرا مدل پوست تیره کامپیوتری بهتر از واقعی
فقط اگر فرانکشتاین بی اطلاع هستید که تعریف "تنوع" را مخدوش می کند
این فقط یک موضوع زمان بود که شأن کلمه تنوع تحت تأثیر قرار گیرد یک شکل تحریف شده از سوءاستفاده که فقط توسط افراد خلاق امکان پذیر است - که هرگز مجبور نیستند به طور منظم با مهارت برخورد کنند ...
افکار
افکار
راه اندازی محیط توسعه OpenCV و C ++ در پروژه های Xcode for Computer Vision
راه اندازی محیط توسعه OpenCV و C ++ در پروژه های Xcode for Computer Vision
Xcode یک IDE رایگان و عالی نه تنها برای ایجاد برنامه های iOS بلکه برای توسعه C ++ و کار بر روی پروژه های بینایی رایانه با استفاده از OpenCV است. پس از مصاحبه با برخی از شرکتها در دره سیلیکون ، متوجه شدم که بسیاری از نرم افزارهای تجاری AR مانند Snap Lenses ، Instagram's Filters ، Apple's Animoji و غیره به زبان C ++ نوشته شده اند تا عملکرد دستگاههای محدود مانند منابع تلفن همراه و رایانه لوحی را به حداکثر برسانند. به بسیاری از ویژگیهای جدید در OpenCV ابتدا در C ++ در دسترس هستند و سپس به پایتون معرفی می شوند زیرا OpenCV بومی C ++ نوشته شده و پیوندهایی را برای پایتون ، جاوا و متلب فراهم می کند.
متأسفانه ، من از پایتون با OpenCV برای دید رایانه برای سهولت استفاده از آنجا که پایتون بسیار خواندنی تر است ، کدگذاری آن راحت تر از C ++ است و تنظیم محیط توسعه نیز آسان تر است. با این حال ، پایتون برای بینایی رایانه ای در صنعت استفاده نمی شود و بنابراین انگیزه ای برای نوشتن این مورد است.
این پست از طریق راه اندازی محیط OpenCV و C ++ در مک بوک ها انجام می شود که در واقع سخت ترین قسمت برای مبتدیان است که از کامپیوتر شروع می کنند. چشم انداز به دلیل فقدان اسناد قابل اعتماد از آنجا که اکثر آموزش های آنلاین به تنظیم محیط برای پایتون می پردازند و درصد بسیار کمی از آنها با راه اندازی آن در Xcode سرو کار دارند.
Xcode را از App Store نصب کنید. App Store را باز کنید و Xcode را جستجو کنید و سپس روی دکمه Get کلیک کنید (در مورد من باز شدن را نشان می دهد زیرا Xcode را نصب کرده ام). از آنجا که اندازه راه اندازی Xcode (9.2) حدود 5.5 گیگابایت است ، بسته به سرعت اینترنت ، ممکن است حدود 30-60 دقیقه طول بکشد.
2. Homebrew را نصب کنید
با عنوان "مدیر بسته گم شده برای macOS" ، کافی است. Homebrew معادل macOS apt-get مبتنی بر اوبونتو/دبیان است. برای نصب کافی است یک ترمینال را باز کرده و جایگذاری کنید:
/usr/bin/ruby -e "$ (curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install) "
3. نصب OpenCV
برای نصب OpenCV با استفاده از brew ، یک ترمینال را باز کرده و جایگذاری کنید:
brew install opencv
با این کار OpenCV 3. باید نصب شود. > 4 نصب pkg-config
pkg-config یک ابزار کمکی است که هنگام کامپایل برنامه ها و کتابخانه ها استفاده می شود. این به شما کمک می کند تا گزینه های کامپایلر صحیح را به جای مقادیر سخت کدگذاری در خط فرمان وارد کنید. این امر برای یافتن پرچمهای پیوند دهنده صحیح برای OpenCV مفید خواهد بود. این امر در مراحل بعدی واضح تر خواهد بود.
برای نصب pkg-config با استفاده از brew ، ترمینال را باز کرده و جایگذاری کنید:
brew نصب pkg-config
5 مشاهده پرچمهای پیوند دهنده OpenCV
برای مشاهده پرچمهای پیوند دهنده برای OpenCV ، اجرا کنید:
pkg-config --cflags --libs opencv
خروجی به شکل زیر است:
-I/usr/local/Cellar/opencv/3.3.1_1/include/opencv -I/usr/local/Cellar/opencv/3.3.1_1/شامل -L/usr/local/Cellar/اوپنسیوی /3.3.1_1 /معاونت -lopencv_stitching -lopencv_superres -lopencv_videostab -lopencv_photo -lopencv_aruco -lopencv_bgsegm -lopencv_bioinspired -lopencv_ccalib -lopencv_dpm -lopencv_face -lopencv_fuzzy -lopencv_img_hash -lopencv_line_descriptor -lopencv_optflow -lopencv_reg -lopencv_rgbd -lopencv_saliency -lopencv_stereo -lopencv_structured_light -lopencv_phase_unwrapping -lopencv_surface_matching - lopencv_tracking -lopencv_datasets -lopencv_text -lopencv_dnn -lopencv_plot -lopencv_xfeatures2d -lopencv_shape -lopencv_video -lopencv_ml -lopencv_ximgproc -lopencv_calib3d -lopencv_features2d -lopencv_highgui -lopencv_videoio -lopencv_flann -lopencv_xobjdetect -lopencv_imgcodecs -lopencv_objdetect -lopencv_xphoto -lopencv_imgproc -lopencv_core
موارد بالا شامل و کتابخانه های OpenCV را به شما نشان می دهد.
در صورتی که فرمان دریافت پرچم های لینکر کار نکند ، ممکن است لازم باشدمحل فایل opencv.pc:
pkg-config --cflags --libs path/to/opencv.pc
فایل opencv.pc من در
<واقع شده است pre>/usr/local/Cellar/opencv/مسیر شما باید در مسیری مشابه باشد.
اجرای کد در ترمینال
خط زیر را که کد OpenCV را با پرچمهای مربوط به پیوند دهنده کامپایل می کند ، جایگذاری کنید.
g ++ $ (pkg -config --cflags --libs opencv) -std = c ++ 11 yourFile.cpp -o yourFileProgram
باینری را اجرا کنید ،
./yourFileProgram
اجرای کد خود در Xcode
 تنظیم زبان به عنوان C ++ برای پروژه ابزار خط فرمان جدید
تنظیم زبان به عنوان C ++ برای پروژه ابزار خط فرمان جدید قبل از انجام مراحل زیر برای اجرای OpenCV C ++ کد در Xcode ، ابتدا باید یک پروژه C ++ در Xcode ایجاد کنید.
تنظیم مسیرهای جستجوی سرصفحه
 تنظیم مسیر جستجوی سرصفحه در Xcode
تنظیم مسیر جستجوی سرصفحه در Xcode برای تنظیم مسیر جستجوی سرصفحه در Xcode ، ابتدا روی پروژه Xcode (در این مورد بینایی کامپیوتر) کلیک کنید و سپس به تنظیمات Build بروید و سپس جستجو کنید for Header Search Paths.
مسیر جستجوی سرصفحه را در مسیر پوشه OpenCV include تنظیم کنید. در مورد من ، این عبارت است: //cdn-images-1.medium.com/max/426/1*Hx5i0eguGinpeAeMeslYeQ.png"> تنظیم مسیر جستجوی کتابخانه در Xcode
در این مورد ، مراحل مشابه تنظیم مسیرهای جستجوی سرصفحه را در بالا دنبال کنید ، اما مسیرهای جستجوی کتابخانه را در نوار جستجو جستجو کنید.
مسیر جستجوی کتابخانه را در مسیر پوشه کتابخانه OpenCV تنظیم کنید. در مورد من این عبارت است: /cdn-images-1.medium.com/max/426/1*PGBx03RXNW2ZNlWqrJgh-g.png"> سایر پرچمهای پیوند دهنده را در Xcode
سایر پرچمهای پیوند دهنده را در نوار جستجو جستجو کنید.
سایر پرچمهای پیوند دهنده را با تمام مقادیر پرچم پس از اجرای دستور pkg-config در بالا تنظیم کنید.
اجرای کد
همه شما آماده اجرای پروژه OpenCV خود در Xcode هستید به Cmd+R را برای اجرای پروژه Xcode خود فشار دهید.
ارسال آرگومان به کد
 روی انتخاب کننده طرح کلیک کنید تا طرح فعال شما تنظیم شود (در این مورد بینایی رایانه) و سپس روی Edit Scheme
روی انتخاب کننده طرح کلیک کنید تا طرح فعال شما تنظیم شود (در این مورد بینایی رایانه) و سپس روی Edit Scheme  در طرح ویرایش ، آرگومان ها یا متغیرهای محیط مورد نیاز کد منبع خود را
در طرح ویرایش ، آرگومان ها یا متغیرهای محیط مورد نیاز کد منبع خود را در صورت تمایل برای ارسال آرگوماناتی مانند یک فایل تصویری به پروژه Xcode شما ، باید مطابق شکل بالا طرح را ویرایش کنید.
استفاده از مسیرهای نسبی فایل
 تنظیم دایرکتوری کار برای مسیرهای نسبی فایل در Xcode
تنظیم دایرکتوری کار برای مسیرهای نسبی فایل در Xcode Xcode از مسیر مطلق تصویر یا منبع استفاده می کند. برای تنظیم مسیرهای نسبی ، باید Working Directory را تنظیم کنید. برای انجام این کار ، در Edit Scheme به برگه Options در Run بروید و Use Custom Working Directory را علامت زده و نام فهرست پروژه را اضافه کنید.
چندین فایل در یک پروژه
پروژه شکست می خورد برای ساخت در صورتی که چندین فایل C ++ برای یک پروژه خاص دارید. در این مورد ، شما باید Targets را در پروژه خود ایجاد کنید ، جایی که هر Target مربوط به یک فایل C ++ است.
مراجع
یک سال در بینایی رایانه ای - قسمت 1 از 4
یک سال در بینایی رایانه ای - قسمت 1 از 4
- قسمت اول: طبقه بندی/محلی سازی ، تشخیص شی و ردیابی اشیا
مقدمه
بینایی کامپیوتر به طور معمول به نظم علمی اعطای توانایی بینایی به ماشین ها ، یا شاید رنگی تر ، که به ماشین ها امکان تجزیه و تحلیل بصری محیط و محرک های درون آنها را می دهد ، اشاره دارد. این فرایند معمولاً شامل ارزیابی یک تصویر ، تصاویر یا فیلم است. انجمن بینایی ماشین ماشین بریتانیا (BMVA) Computer Vision را به عنوان "استخراج ، تجزیه و تحلیل و درک خودکار اطلاعات مفید از یک تصویر یا دنباله ای از تصاویر" تعریف می کند. نقطه مقابل تعریفی مکانیکی از بینایی ، که برای نشان دادن اهمیت و پیچیدگی میدان بینایی رایانه ای مفید است. درک واقعی از محیط زیست ما تنها از طریق نمایش بصری به دست نمی آید. در عوض ، نشانه های بصری از طریق عصب بینایی به قشر بینایی اولیه منتقل می شوند و توسط مغز تفسیر می شوند ، به معنای بسیار سبک. تفاسیر به دست آمده از این اطلاعات حسی شامل کلیت برنامه های طبیعی و تجربیات ذهنی ما می شود ، یعنی چگونه تکامل ما را برای بقا و آنچه در سراسر جهان در مورد جهان یاد می گیریم ، وادار کرده است.
از این نظر ، بینایی فقط به انتقال تصاویر برای تفسیر مربوط می شود. در حالی که محاسبه تصاویر گفته شده بیشتر شبیه اندیشه یا شناخت است و از بسیاری از توانایی های مغز استفاده می کند. از این رو ، بسیاری معتقدند که Computer Vision ، درک واقعی از محیط های بصری و زمینه های آنها ، به دلیل تسلط بر حوزه های مختلف ، راه را برای تکرارهای آینده هوش مصنوعی قوی هموار می کند. از آنجا که ما هنوز در مراحل جنینی این زمینه جذاب هستیم. این قطعه به سادگی قصد دارد تا بزرگترین پیشرفت های چشم انداز رایانه ای 2016 را روشن کند. و امیدوارم برخی از این پیشرفت ها را در ترکیبی سالم از تعاملات اجتماعی مورد انتظار در کوتاه مدت و ، در صورت لزوم ، پیش بینی های زبان به گونه ای از پایان زندگی آنطور که ما می شناسیم ، پایه گذاری کنیم.
در حالی که کار ما همیشه تا آنجا که ممکن است نوشته شده است ، بخشهای داخل این قطعه خاص ممکن است به دلیل موضوع مورد نظر ، گاهی مایل باشند. ما در کل تعاریف ابتدایی ارائه می دهیم ، اما اینها فقط درک آسان مفاهیم کلیدی را ارائه می دهند. برای حفظ تمرکز ما بر روی کارهایی که در سال 2016 تولید شده است ، غالباً به منظور اختصار مواردی حذف می شوند.
یکی از این حذفهای آشکار مربوط به عملکرد شبکه های عصبی کانولوشن (از این پس CNN ها یا ConvNets) است که در همه جا وجود دارد. زمینه بینایی کامپیوتر موفقیت AlexNet [2] در 2012 ، معماری CNN که رقبای ImageNet را کور کرد ، محرک یک انقلاب عملاً در این زمینه بود ، با محققان متعددی که رویکردهای مبتنی بر شبکه عصبی را به عنوان بخشی از دوره جدید علوم طبیعی "Computer Vision" اتخاذ کردند. . [3]
بیش از چهار سال بعد و نسخه های CNN هنوز بخش عمده ای از معماری های شبکه عصبی جدید را برای کارهای بینایی تشکیل می دهند و محققان آنها را مانند لگو بازسازی می کنند. گواهی م workingثر بر قدرت اطلاعات متن باز و یادگیری عمیق. با این حال ، توضیح CNN ها می تواند به راحتی چندین پست را در بر بگیرد و بهتر است به کسانی که تخصص عمیق تری در این زمینه و علاقه به ساختن دارند ، سپرده شود.پیچیده قابل درک است.
برای خوانندگان معمولی که مایلند قبل از شروع به کار سریع عمل کنند ، دو منبع اول را در زیر توصیه می کنیم. برای کسانی که مایل به پیشرفت هستند ، ما منابع زیر را برای تسهیل این امر دستور داده ایم: و عملکردهای پشت CNN ها. [4]
برای کسانی که مایل هستند برای درک بیشتر در مورد شبکه های عصبی و عمیق یادگیری ، ما پیشنهاد می کنیم:
به طور کلی این قطعه جدا نشده و اسپاسمودیک است ، بازتابی از هیجان و روحیه نویسندگان که قرار بود بخش به بخش مورد استفاده قرار گیرد. اطلاعات با استفاده از روشهای اکتشافی و قضاوت های خود تقسیم بندی می شوند ، که به دلیل تأثیر گسترده در بسیاری از آثار ارائه شده ، سازش لازم است.
امیدواریم که خوانندگان از تجمع اطلاعات ما در اینجا برای پیشبرد اطلاعات خود بهره مند شوند. دانش ، صرف نظر از تجربه قبلی. com/max/426/1*Q_zw5-Mu8eksQCveTK_4vQ.png ">
طبقه بندی/محلی سازی
وظیفه طبقه بندی ، وقتی به تصاویر مربوط می شود ، عموماً به اختصاص یک برچسب به کل تصویر ، به عنوان مثال "گربه" با فرض این ، Localization ممکن است به یافتن جایی که شی در تصویر گفته شده است اشاره داشته باشد ، که معمولاً با خروجی نوعی جعبه محدود کننده در اطراف شی نشان داده می شود. تکنیک های طبقه بندی فعلی در ImageNet [9] احتمالاً از مجموعه ای از افراد آموزش دیده پیشی گرفته است. [10] به همین دلیل ، ما بر بخش های بعدی وبلاگ تأکید بیشتری می کنیم.
 منبع: فی فی لی ، آندریج کارپاتی و جاستین جانسون (2016) cs231n ، سخنرانی 8-اسلاید 8 ، محلی سازی و تشخیص فضایی (01/02/2016). در دسترس: http://cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf
منبع: فی فی لی ، آندریج کارپاتی و جاستین جانسون (2016) cs231n ، سخنرانی 8-اسلاید 8 ، محلی سازی و تشخیص فضایی (01/02/2016). در دسترس: http://cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf با این حال ، معرفی مجموعه داده های بزرگتر با افزایش تعداد کلاسها [11] به احتمال زیاد معیارهای جدیدی برای پیشرفت در آینده ی نزدیک. در این زمینه ، فرانسوا شولت ، خالق Keras ، [12] تکنیک های جدیدی از جمله معماری معمول Xception را در مجموعه داده داخلی Google با بیش از 350 میلیون تصویر چند برچسب حاوی 17000 کلاس اعمال کرده است. [13،14]
 توجه: چالش تشخیص بصری در مقیاس بزرگ ImageNet (ILSVRC). تغییر در نتایج از سال 2011 تا 2012 ناشی از ارسال AlexNet. برای مروری بر الزامات چالش مربوط به طبقه بندی و محلی سازی مراجعه کنید: http://www.image-net.org/challenges/LSVRC/2016/index#comp
توجه: چالش تشخیص بصری در مقیاس بزرگ ImageNet (ILSVRC). تغییر در نتایج از سال 2011 تا 2012 ناشی از ارسال AlexNet. برای مروری بر الزامات چالش مربوط به طبقه بندی و محلی سازی مراجعه کنید: http://www.image-net.org/challenges/LSVRC/2016/index#comp منبع: جیا دنگ (2016). بومی سازی شی ILSVRC2016: مقدمه ، نتایج. اسلاید 2. موجود: http://image-net.org/challenges/talks/2016/ILSVRC2016_10_09_clsloc.pdf
برداشتهای جالب از ImageNet LSVRC (2016):
تشخیص شی
همانطور که می توان تصور کرد فرآیند تشخیص شی دقیقاً همان کار را انجام می دهد ، اشیاء درون تصاویر را تشخیص می دهد. تعریف ارائه شده برای تشخیص شی توسط ILSVRC 2016 [20] شامل خروجی جعبه های محدود کننده و برچسب ها برای اشیاء جداگانه است. این امر با اعمال طبقه بندی و بومی سازی در بسیاری از اشیاء به جای یک شیء غالب ، متفاوت از وظیفه طبقه بندی/بومی سازی است.
 توجه: تصویر نمونه ای از تشخیص چهره ، تشخیص شیء در یک کلاس واحد است. نویسندگان یکی از مسائل پایدار در تشخیص اشیاء را تشخیص اجسام کوچک عنوان می کنند. آنها با استفاده از چهره های کوچک به عنوان یک کلاس آزمایشی ، نقش تغییر ناپذیری مقیاس ، وضوح تصویر و استدلال زمینه ای را بررسی می کنند. منبع: هو و رامانان (2016 ، ص 1) [21]
توجه: تصویر نمونه ای از تشخیص چهره ، تشخیص شیء در یک کلاس واحد است. نویسندگان یکی از مسائل پایدار در تشخیص اشیاء را تشخیص اجسام کوچک عنوان می کنند. آنها با استفاده از چهره های کوچک به عنوان یک کلاس آزمایشی ، نقش تغییر ناپذیری مقیاس ، وضوح تصویر و استدلال زمینه ای را بررسی می کنند. منبع: هو و رامانان (2016 ، ص 1) [21] یکی از گرایش های اصلی سال 2016 در تشخیص اشیاء ، حرکت به سمت یک سیستم تشخیص سریعتر و کارآمدتر بود. این در رویکردهایی مانند YOLO ، SSD و R-FCN به عنوان حرکتی برای به اشتراک گذاری محاسبه روی یک تصویر کامل قابل مشاهده بود. بنابراین ، خود را از زیر شبکه های پرهزینه مرتبط با تکنیک های سریع/سریعتر R-CNN متمایز می کنند. این به طور معمول به عنوان "آموزش/یادگیری پایان به پایان" و ویژگی ها در سراسر این بخش نامیده می شود.
دلیل کلی این است که از تمرکز الگوریتم های جداگانه بر مشکلات فرعی مربوطه جدا خودداری کنید زیرا این امر به طور معمول آموزش را افزایش می دهد. زمان و می تواند دقت شبکه را کاهش دهد. گفته می شود که این انطباق کامل با شبکه ها معمولاً پس از راه حل های اولیه زیر شبکه صورت می گیرد و به همین دلیل ، یک بهینه سازی گذشته نگر است. با این حال ، تکنیک های سریع/سریعتر R-CNN بسیار م remainثر است و هنوز هم به طور گسترده برای تشخیص شی استفاده می شود.
 توجه: محور Y mAP (میانگین دقت متوسط) و محور X تنوع متا معماری را در هر استخراج کننده ویژگی (VGG ، MobileNet ... Inception ResNet V2) نمایش می دهد. علاوه بر این ، MAP کوچک ، متوسط و بزرگ به ترتیب میانگین دقت اجسام کوچک ، متوسط و بزرگ را توصیف می کند. از آنجا که چنین دقت "طبقه بندی شده توسط اندازه شی ، معماری فرا و استخراج ویژگی" و "وضوح تصویر بر روی 300 ثابت شده است". در حالی که R-CNN سریعتر نسبتاً در نمونه فوق عملکرد خوبی دارد ، شایان ذکر است که معماری متا بطور قابل ملاحظه ای کندتر از رویکردهای اخیر است ، مانند R-FCN.
توجه: محور Y mAP (میانگین دقت متوسط) و محور X تنوع متا معماری را در هر استخراج کننده ویژگی (VGG ، MobileNet ... Inception ResNet V2) نمایش می دهد. علاوه بر این ، MAP کوچک ، متوسط و بزرگ به ترتیب میانگین دقت اجسام کوچک ، متوسط و بزرگ را توصیف می کند. از آنجا که چنین دقت "طبقه بندی شده توسط اندازه شی ، معماری فرا و استخراج ویژگی" و "وضوح تصویر بر روی 300 ثابت شده است". در حالی که R-CNN سریعتر نسبتاً در نمونه فوق عملکرد خوبی دارد ، شایان ذکر است که معماری متا بطور قابل ملاحظه ای کندتر از رویکردهای اخیر است ، مانند R-FCN. منبع: هوانگ و همکاران. (2016 ، ص 9) [31]
هوانگ و همکاران (2016) [32] مقاله ای ارائه می دهد که مقایسه عمیقی بین R-FCN ، SSD و R-CNN سریعتر ارائه می دهد. با توجه به مسائل مربوط به مقایسه دقیق تکنیک های یادگیری ماشین (ML) ، ما می خواهیم در اینجا به مزایای تولید رویکرد استاندارد اشاره کنیم. آنها به این معماری ها به عنوان "معماری فرا" نگاه می کنند زیرا می توانند با انواع مختلف استخراج کننده های ویژگی مانند ResNet یا Inception ترکیب شوند. ، استخراج ویژگی و وضوح تصویر. به عنوان مثال ، انتخاب ویژگی های استخراج تغییرات زیادی بین معماری متا ایجاد می کند.
روند تشخیص ارزان قیمت و کارآمد در عین حفظ دقت مورد نیاز برای برنامه های تجاری در زمان واقعی ، به ویژه در برنامه های رانندگی خودران ، همچنین توسط مقالات SqueezeDet [33] و PVANet [34] نشان داده می شود. در حالی که یک شرکت چینی ، DeepGlint ، مثال خوبی از تشخیص شیء در عمل به عنوان یکپارچه دوربین مدار بسته ، البته به صورت مبهم Orwellian ارائه می دهد: ویدئو. [35]
نتایج از ILSVRC و COCO Detection Challenge
COCO [36] (اشیاء مشترک در زمینه) یک مجموعه داده تصویری دیگر است. با این حال ، این دستگاه نسبت به گزینه های دیگر مانند ImageNet نسبتاً کوچکتر و تنظیم شده است ، با تمرکز بر تشخیص شی در زمینه وسیع تر درک صحنه. سازمان دهندگان سالانه میزبان چالش تشخیص شیء ، تقسیم بندی هستندو نکات کلیدی نتایج تشخیص از ILSVRC [37] و COCO [38] Detection Challenge عبارتند از: برنده 109 مورد از 200 دسته بندی شی. AP
در بررسی نتایج تشخیص در سال 2016 ، ImageNet اظهار داشت که "MSRAVC 2015" برای عملکرد [معرفی ResNets در رقابت] بسیار بالا بود. عملکرد در همه کلاس ها در ورودی ها بهبود یافته است. بومی سازی در هر دو چالش بسیار بهبود یافته است. بهبود نسبی بالا در موارد اجسام کوچک '(ImageNet، 2016). [39]
ردیابی موضوع
اشاره به فرایند پیروی از یک شیء مورد علاقه خاص یا چند شیء ، در یک صحنه معین. به طور سنتی در تعاملات ویدئویی و دنیای واقعی کاربردهایی دارد که در آن مشاهدات پس از تشخیص اولیه شیء انجام می شود. این فرایند برای سیستم های رانندگی خودران برای مثال بسیار مهم است. با نرخ فریم بیش از زمان واقعی عمل می کند. این مقاله تلاش می کند تا فقدان غنی موجود برای ردیابی مدلها از روشهای سنتی یادگیری آنلاین را برطرف کند.
ویدیوی GOTURN (ردیابی اشیاء عمومی با استفاده از شبکه های رگرسیون) موجود است: ویدئو [ 42]
ما خوانندگان را تشویق می کنیم تا این مقاله را از طریق وب سایت خود مشاهده کنند ، زیرا ما شامل محتوای تعبیه شده و عملکردهای ناوبری آسان برای ایجاد گزارش تا حد امکان پویا هستیم. ما از طریق وب سایت خود هیچ درآمدی نداریم و می خواهیم آن را تا آنجا که ممکن است برای خوانندگان جذاب و شهودی باشد ، بنابراین هرگونه بازخورد درباره ارائه در آنجا با تمام وجود مورد استقبال ما قرار می گیرد!
با ما تماس بگیرید ، سپاس فراوان ،
The M Tank

مراجع به ترتیب ظاهر
قطعه کامل در آدرس زیر قابل دسترسی است: http: //www.themtank.org/publications/a-year-in-computer-vision
[1] British Machine Vision Association (BMVA). 2016. بینایی کامپیوتری چیست؟ [آنلاین] موجود در: http://www.bmva.org/visionoverview [دسترسی 21/12/2016]
[2] Krizhevsky، A.، Sutskever، I. and Hinton، GE 2012. طبقه بندی ImageNet با شبکه های عصبی متحرک عمیق ، NIPS 2012: سیستم های پردازش اطلاعات عصبی ، دریاچه تاهو ، نوادا. موجود: http://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf
[3] کوهن ، تی اس اس 1962. ساختار انقلاب های علمی. ویرایش چهارم ایالات متحده: انتشارات دانشگاه شیکاگو.
[4] Karpathy، A. 2015. نظر یک شبکه عصبی عمیق در مورد #selfie شما چیست. [وبلاگ] وبلاگ Andrej Karpathy. موجود: http://karpathy.github.io/2015/10/25/selfie/[دسترسی: 21/12/2016]
[5] Quora. 2016. شبکه عصبی کانولوشن چیست؟ [آنلاین] موجود: https://www.quora.com/What-is-a-convolutional-neural-network [دسترسی: 21/12/2016]
[6] دانشگاه استنفورد. 2016. شبکه های عصبی تحولی برای تشخیص بصری. [آنلاین] CS231n. موجود: http://cs231n.stanford.edu/[دسترسی 21/12/2016]
[7] Goodfellow و همکاران. 2016. یادگیری عمیق. مطبوعات MIT [آنلاین] http://www.deeplearningbook.org/[دسترسی: 21/12/2016] توجه: فصل 9 ، شبکه های تحول آفرین [موجود: http://www.deeplearningbook.org/contents/convnets.html ]
[8] نیلسن ، م. 2017. شبکه های عصبی و یادگیری عمیق. [آنلاین] کتاب الکترونیکی. موجود: http://neuralnetworksanddeeplearning.com/index.html [دسترسی: 06/03/2017].
[9] ImageNet به مجموعه داده های تصویری محبوب برای Computer Vision اشاره دارد. هر سال شرکت کنندگان در مجموعه ای از وظایف مختلف به نام ImageNet Large Scale Visual Recognition Challenge (ILSVRC) رقابت می کنند. موجود: http://image-net.org/challenges/LSVRC/2016/index
[10] به "آنچه از رقابت با ConvNet در ImageNet آموختم" توسط آندره کارپاتی مراجعه کنید. پست وبلاگ جزئیات سفر نویسنده برای ارائه معیار انسانی در برابر مجموعه داده ILSVRC 2014 است. میزان خطا تقریبا 5.1 vers در مقابل خطای طبقه بندی GoogLeNet 6.8 then بود. موجود: http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
[11] مشاهده جدید مجموعه داده ها بعدا در این قسمت.
[12] Keras یک کتابخانه یادگیری عمیق مبتنی بر شبکه عصبی است: https://keras.io/
[13] Chollet، F. 2016. جاسازی برچسب اطلاعاتی-نظری برای طبقه بندی تصویر در مقیاس بزرگ. [آنلاین] arXiv: 1607.05691. موجود: arXiv: 1607.05691v1
[14] Chollet، F. 2016. استثنا: یادگیری عمیق با ترکیبات عمیق تفکیک پذیر. [آنلاین] arXiv: 1610.02357. موجود: arXiv: 1610.02357v2
[15] مجموعه داده Places2 ، جزئیات موجود: http://places2.csail.mit.edu/. همچنین به بخش مجموعه داده های جدید مراجعه کنید.
[16] Hikvision.2016. Hikvision در چالش ImageNet 2016 رتبه 1 را در طبقه بندی صحنه کسب کرد. [آنلاین] دفتر اخبار امنیتی. موجود: http://www.securitynewsdesk.com/hikvision-ranked-no-1-scene-classification-imagenet-2016-challenge/[دسترسی: 20/03/2017].
[17] برای اطلاعات بیشتر به شبکه های باقیمانده در قسمت چهارم این نشریه مراجعه کنید.
[18] جزئیات موجود در زیر اطلاعات تیم Trimps-Soushen از: http://image-net.org/challenges/LSVRC/2016/results
[19] Xie، S.، Girshick، R.، Dollar، P.، Tu، Z. & He، K. 2016. مجموع تحولات باقیمانده برای شبکه های عصبی عمیق. [آنلاین] arXiv: 1611.05431. موجود: arXiv: 1611.05431v1
[20] ImageNet Large Scale Visual Recognition Challenge (2016) ، قسمت دوم ، موجود: http://image-net.org/challenges/LSVRC/2016/[دسترسی: 22/11/2016]
[21] هو و رامانان. 2016. یافتن چهره های ریز. [آنلاین] arXiv: 1612.04402. موجود: arXiv: 1612.04402v1
[22] Liu et al. 2016. SSD: آشکارساز چند شبه تک شات. [آنلاین] arXiv: 1512.02325v5. موجود: arXiv: 1512.02325v5
[23] Redmon، J. Ferhadi، A. 2016. YOLO9000: بهتر ، سریعتر ، قوی تر. [آنلاین] arXiv: 1612.08242v1. موجود: arXiv: 1612.08242v1
[24] YOLO مخفف عبارت "You Only Look Only Once" است.
[25] Redmon et al. 2016. شما فقط یکبار نگاه می کنید: یکپارچه ، تشخیص اشیاء در زمان واقعی. [آنلاین] arXiv: 1506.02640. موجود: arXiv: 1506.02640v5
[26] ردمون. 2017. YOLO: تشخیص شی در زمان واقعی. [وب سایت] pjreddie.com. موجود: https://pjreddie.com/darknet/yolo/[دسترسی: 01/03/2017].
[27] لین و همکاران 2016. ویژگی شبکه های هرمی برای تشخیص شی. [آنلاین] arXiv: 1612.03144. موجود: arXiv: 1612.03144v1
[28] تحقیقات هوش مصنوعی فیس بوک
[29] مجموعه داده های تصویری Objects in Context (COCO)
[30] Dai و همکاران 2016. R-FCN: تشخیص شی از طریق شبکه های کاملاً تحول محور مبتنی بر منطقه. [آنلاین] arXiv: 1605.06409. موجود: arXiv: 1605.06409v2
[31] هوانگ و همکاران. 2016. جابجایی سرعت/دقت برای آشکارسازهای اجسام پیچشی مدرن. [آنلاین] arXiv: 1611.10012. موجود: arXiv: 1611.10012v1
[32] همان
[33] وو و همکاران. 2016. SqueezeDet: شبکه های عصبی متحد ، کوچک ، کم مصرف و کاملاً متحرک برای تشخیص شیء در زمان واقعی برای رانندگی مستقل. [آنلاین] arXiv: 1612.01051. موجود: arXiv: 1612.01051v2
[34] Hong et al. 2016. PVANet: شبکه های عصبی سبک عمیق برای تشخیص اشیاء در زمان واقعی. [آنلاین] arXiv: 1611.08588v2. موجود: arXiv: 1611.08588v2
[35] DeepGlint Official. 2016. DeepGlint CVPR2016. [آنلاین] Youtube.com. موجود: https://www.youtube.com/watch؟v=xhp47v5OBXQ [دسترسی: 01/03/2017].
[36] COCO - Objects Common in Common. 2016. [وب سایت] موجود: http://mscoco.org/[دسترسی: 04/01/2017].
[37] نتایج ILSRVC برگرفته از: ImageNet. 2016. چالش تشخیص بصری در مقیاس بزرگ 2016.
[وب سایت] تشخیص شی. در دسترس: http://image-net.org/challenges/LSVRC/2016/results [دسترسی: 04/01/2017].
[38] نتایج چالش تشخیص COCO برگرفته از: COCO-Objects Common مشترک. 2016. تابلوی تشخیص [وب سایت] mscoco.org. موجود: http://mscoco.org/dataset/#detections-leaderboard [دسترسی: 05/01/2017].
[39] ImageNet. 2016. [آنلاین] ارائه کارگاه ، اسلاید 31. موجود: http://image-net.org/challenges/talks/2016/ECCV2016_ilsvrc_coco_detection_segmentation.pdf [دسترسی: 06/01/2017].
[ 40] برتینتو و همکاران. 2016. شبکه های سیامی کاملاً متحول برای ردیابی اشیاء. [آنلاین] arXiv: 1606.09549. موجود: https://arxiv.org/abs/1606.09549v2
[41] Held et al. 2016. آموزش ردیابی در 100 FPS با شبکه های رگرسیون عمیق. [آنلاین] arXiv: 1604.01802. موجود: https://arxiv.org/abs/1604.01802v2
[42] David Held. 2016. GOTURN - یک ردیاب شبکه عصبی. [آنلاین] YouTube.com. در دسترس: https://www.youtube.com/watch؟v=kMhwXnLgT_I [دسترسی: 03/03/2017].
[43] Gladh et al. 2016. ویژگی های حرکت عمیق برای ردیابی بصری. [آنلاین] arXiv: 1612.06615. موجود: arXiv: 1612.06615v1
[44] گایدون و همکاران 2016. دنیای مجازی به عنوان پروکسی برای تجزیه و تحلیل ردیابی چند شیء. [آنلاین] arXiv: 1605.06457. موجود: arXiv: 1605.06457v1
[45] لی و همکاران 2016. ردیابی جهانی بهینه اشیاء با شبکه های کاملاً متحول. [آنلاین] arXiv: 1612.08274. موجود: arXiv: 1612.08274v1